



原文:https://www.cnblogs.com/rjzheng/p/10510174.html
知识点总结
1.数据库默认隔离级别: mysql ---repeatable,oracle,sql server ---read commited
2.mysql binlog的格式三种:statement,row,mixed
3.为什么mysql用的是repeatable而不是read committed:在 5.0之前只有statement一种格式,而主从复制存在了大量的不一致,故选用repeatable
4.为什么默认的隔离级别都会选用read commited 原因有二:repeatable存在间隙锁会使死锁的概率增大,在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行
2.在RC级用别下,主从复制用什么binlog格式:row格式,是基于行的复制!
引言
开始我们的内容,相信大家一定遇到过下面的一个面试场景
面试官:“讲讲mysql有几个事务隔离级别?”
你:“读未提交,读已提交,可重复读,串行化四个!默认是可重复读”
面试官:“为什么mysql选可重复读作为默认的隔离级别?”
(你面露苦色,不知如何回答!)
面试官:"你们项目中选了哪个隔离级别?为什么?"
你:“当然是默认的可重复读,至于原因。。呃。。。”
(然后你就可以回去等通知了!)
为了避免上述尴尬的场景,请继续往下阅读! Mysql默认的事务隔离级别是可重复读(Repeatable Read),那互联网项目中Mysql也是用默认隔离级别,不做修改么? OK,不是的,我们在项目中一般用读已提交(Read Commited)这个隔离级别! what!居然是读已提交,网上不是说这个隔离级别存在不可重复读和幻读问题么?不用管么?好,带着我们的疑问开始本文!
正文
我们先来思考一个问题,在Oracle,SqlServer中都是选择读已提交(Read Commited)作为默认的隔离级别,为什么Mysql不选择读已提交(Read Commited)作为默认隔离级别,而选择可重复读(Repeatable Read)作为默认的隔离级别呢?
Why?Why?Why? 这个是有历史原因的,当然要从我们的主从复制开始讲起了! 主从复制,是基于什么复制的? 是基于binlog复制的!这里不想去搬binlog的概念了,就简单理解为binlog是一个记录数据库更改的文件吧~ binlog有几种格式? OK,三种,分别是
- statement:记录的是修改SQL语句
- row:记录的是每行实际数据的变更
- mixed:statement和row模式的混合
那Mysql在5.0这个版本以前,binlog只支持STATEMENT这种格式!而这种格式在读已提交(Read Commited)这个隔离级别下主从复制是有bug的,因此Mysql将可重复读(Repeatable Read)作为默认的隔离级别!
接下来,就要说说当binlog为STATEMENT格式,且隔离级别为读已提交(Read Commited)时,有什么bug呢?如下图所示,在主(master)上执行如下事务
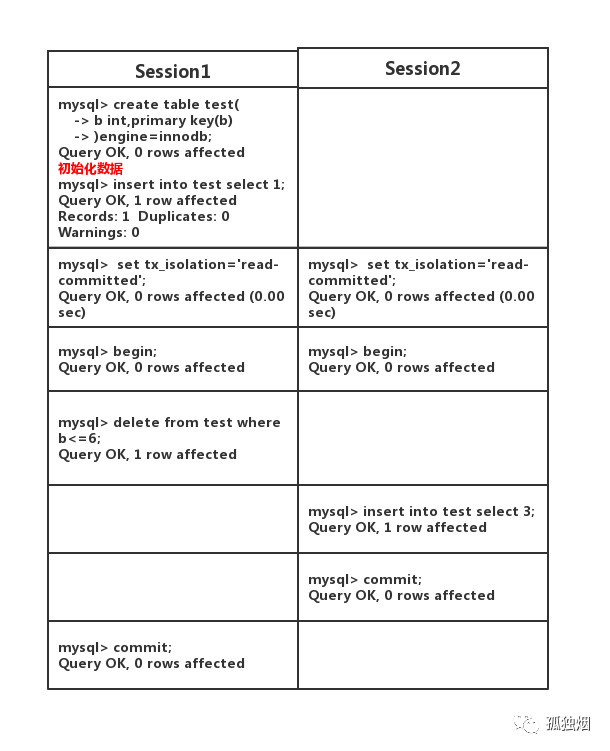 此时在主(master)上执行下列语句
此时在主(master)上执行下列语句
select * from test; 输出如下
| b | +---+ | 3 |
1 row in set
但是,你在此时在从(slave)上执行该语句,得出输出如下
Empty set 这样,你就出现了主从不一致性的问题!原因其实很简单,就是在master上执行的顺序为先删后插!而此时binlog为STATEMENT格式,它记录的顺序为先插后删!从(slave)同步的是binglog,因此从机执行的顺序和主机不一致!就会出现主从不一致! 如何解决? 解决方案有两种! (1)隔离级别设为可重复读(Repeatable Read),在该隔离级别下引入间隙锁。当Session 1执行delete语句时,会锁住间隙。那么,Ssession 2执行插入语句就会阻塞住! (2)将binglog的格式修改为row格式,此时是基于行的复制,自然就不会出现sql执行顺序不一样的问题!奈何这个格式在mysql5.1版本开始才引入。因此由于历史原因,mysql将默认的隔离级别设为可重复读(Repeatable Read),保证主从复制不出问题!
那么,当我们了解完mysql选可重复读(Repeatable Read)作为默认隔离级别的原因后,接下来我们将其和读已提交(Read Commited)进行对比,来说明为什么在互联网项目为什么将隔离级别设为读已提交(Read Commited)!
对比
ok,我们先明白一点!项目中是不用读未提交(Read UnCommitted)和串行化(Serializable)两个隔离级别,原因有二
采用读未提交(Read UnCommitted),一个事务读到另一个事务未提交读数据,这个不用多说吧,从逻辑上都说不过去! 采用串行化(Serializable),每个次读操作都会加锁,快照读失效,一般是使用mysql自带分布式事务功能时才使用该隔离级别!(笔者从未用过mysql自带的这个功能,因为这是XA事务,是强一致性事务,性能不佳!互联网的分布式方案,多采用最终一致性的事务解决方案!) 也就是说,我们该纠结都只有一个问题,究竟隔离级别是用读已经提交呢还是可重复读? 接下来对这两种级别进行对比,讲讲我们为什么选读已提交(Read Commited)作为事务隔离级别! 假设表结构如下
CREATE TABLE test (
id int(11) NOT NULL,
color varchar(20) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB
数据如下
| id | color |
|---|---|
| 1 | red |
| 2 | white |
| 5 | red |
| 7 | white |
为了便于描述,下面将
可重复读(Repeatable Read),简称为RR; 读已提交(Read Commited),简称为RC; 缘由一:在RR隔离级别下,存在间隙锁,导致出现死锁的几率比RC大的多! 此时执行语句
select * from test where id <3 for update; 在RR隔离级别下,存在间隙锁,可以锁住(2,5)这个间隙,防止其他事务插入数据! 而在RC隔离级别下,不存在间隙锁,其他事务是可以插入数据!
ps:在RC隔离级别下并不是不会出现死锁,只是出现几率比RR低而已!
缘由二:在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行 此时执行语句
update test set color = 'blue' where color = 'red'; 在RC隔离级别下,其先走聚簇索引,进行全部扫描。加锁如下:

但在实际中,MySQL做了优化,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁。
实际加锁如下
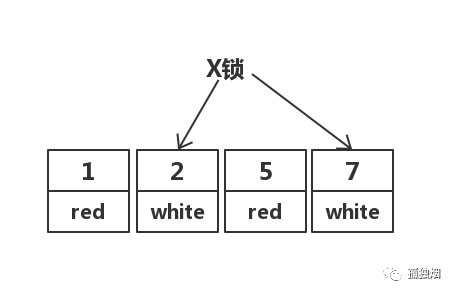
然而,在RR隔离级别下,走聚簇索引,进行全部扫描,最后会将整个表锁上,如下所示

缘由三:在RC隔离级别下,半一致性读(semi-consistent)特性增加了update操作的并发性! 在5.1.15的时候,innodb引入了一个概念叫做“semi-consistent”,减少了更新同一行记录时的冲突,减少锁等待。 所谓半一致性读就是,一个update语句,如果读到一行已经加锁的记录,此时InnoDB返回记录最近提交的版本,由MySQL上层判断此版本是否满足update的where条件。若满足(需要更新),则MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)! 具体表现如下: 此时有两个Session,Session1和Session2! Session1执行
update test set color = 'blue' where color = 'red'; 先不Commit事务! 与此同时Ssession2执行
update test set color = 'blue' where color = 'white'; session 2尝试加锁的时候,发现行上已经存在锁,InnoDB会开启semi-consistent read,返回最新的committed版本(1,red),(2,white),(5,red),(7,white)。MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)! 而在RR隔离级别下,Session2只能等待!
两个疑问 在RC级别下,不可重复读问题需要解决么? 不用解决,这个问题是可以接受的!毕竟你数据都已经提交了,读出来本身就没有太大问题!Oracle的默认隔离级别就是RC,你们改过Oracle的默认隔离级别么?
在RC级别下,主从复制用什么binlog格式? OK,在该隔离级别下,用的binlog为row格式,是基于行的复制!Innodb的创始人也是建议binlog使用该格式!
总结 本文啰里八嗦了一篇文章只是为了说明一件事,互联网项目请用:读已提交(Read Commited)这个隔离级别!


评论区